Nutzung des Formats "BMEcat" als Grundlage für die Datenhaltung in PIM
Unternehmen, die ein MDM oder PIM-System als Drehscheibe und Konsolidierungsplattform für Ihre Stammdaten einführen, stehen zu Projektbeginn häufig vor der Frage, wie der optimale Datensatz und die optimale Datenstruktur innerhalb eines solchen Systems auszusehen hat. Aufgabe des MDM/PIM ist, als universeller Datenspeicher für diverse Systeme zu dienen, um diese mit Stammdaten zu versorgen. Diese Zielsysteme können grob in 2 Kategorien unterteilt werden:
a) vorhandene Alt-Systeme mit historisch gewachsenen und auf älteren Konzepten basierenden Strukturen (Beispiele: Oracle Rdb, IMS von IBM, Relationale Datenbanken)
b) neu geplante Systeme, häufig mit dem Einsatzgebiet eCommerce, eProcurement, BI oder CRM, die Ihre Daten im Hintergrund in moderneren Strukuren speichern (XML-Datenbanken, Objekt-Datenbank, NO-SQL, Domain-Struktur u.v.m.)
Anforderungen zusammenführen
Daraus ergibt sich für die Planung eines Stammdatenmanagement-Systems fast automatisch ein Dilema: Wie können die sehr unterschiedlichen Anforderungen an einen Datensatz über ein in sich schlüssiges Konzept erfüllt werden?
Dabei ist die einfache Bildung von Anforderungs-Schnittmengen oft schwierig oder nicht möglich. Zudem wünscht man sich einen Datenpool mit standardisierten Datensätzen/Attributen für den Datenaustausch mit externen Systemen wie auch standardisierte Hierarchien. Die Datenstrukturen des MDM- oder PIM-Systems sollen zudem aktuellste Anforderungen die durch die Zunahme von Internet-Aktivitäten bedingt sind, erfüllen. Spätestens an dieser Stelle kann im Projekt noch ein Kompetenzproblem hinzukommen: Fachleute, die das nötige Hintergrundwissen und die Erfahrungen haben, um plattformübergreifende Datenstrukturen zu definieren, sind rar.
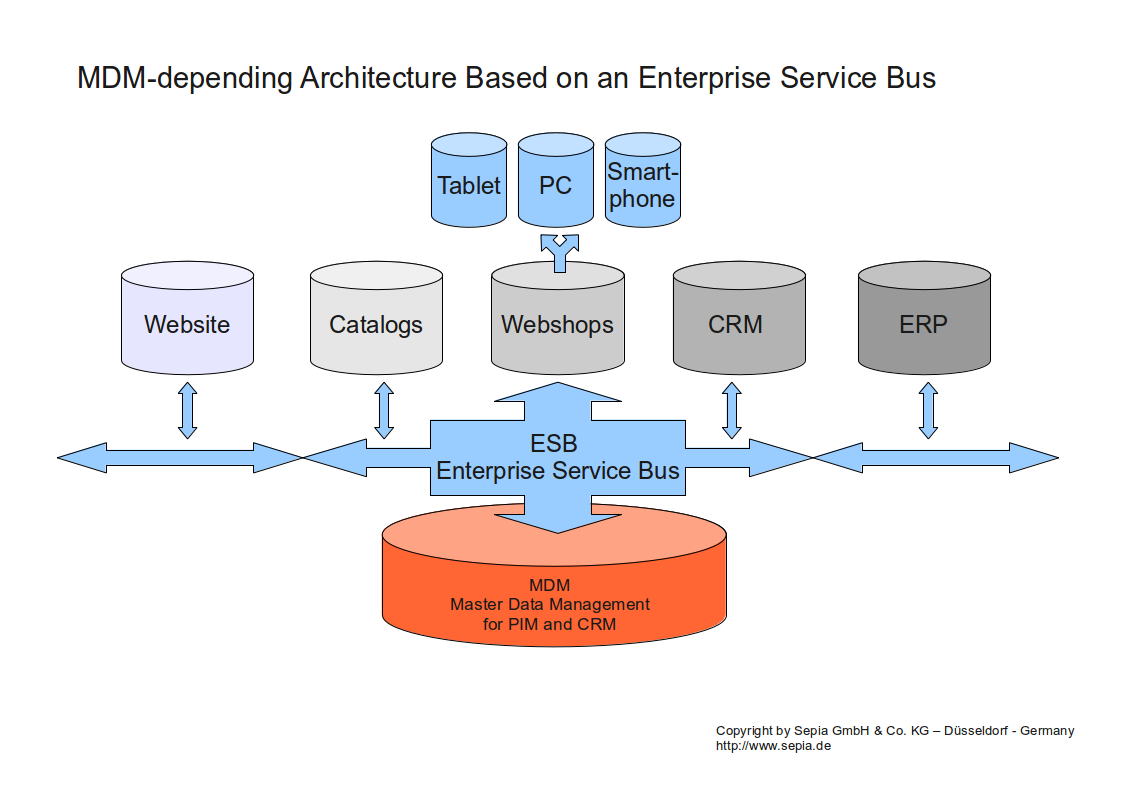
MDM integriert in eine Systemlandschaft mittels ESB
Mögliche Strategien
Als mögliche Lösungsansätze für die Optimierung der Datenstrukturen werden in der Regel diese Strategien in Betracht gezogen:
a) Datenstrukturen optimiert für ERP oder CRM
Empfehlung: suboptimal, da bei diesem Konzept mögliche andere Zielsysteme stark vernachlässigt werden.
b) Datenstrukturen optimiert für Shopsysteme/eCommerce
Empfehlung: nicht optimal, Shop-Systeme beinhalten zwar häufig ein Attribut-System berücksichtigen aber meist nur die Aspekte, die für den Abverkauf im Netz wichtig sind - weitere Informationen, die für interne Mitarbeiter relevant sind, weren nicht berücksichtigt.
c) Datenstrukturen von Grund auf selbständig definiert - ohne Anlehnung an Standards
Empfehlung: fehlerbehaftet, externe Kompetenz nötig.
d) Standardisierte Datenstrukturen in Anlehnung an BMECat
Empfehlung: kostengünstig durch geringen Beratungsaufwand
Kompetenzen diverser Fachleute sind bereits in das Format eingeflossen. Zur Strukturierung von Stammdaten und zur Bildung von Klassen ähnlicher Produkte und zum Beschreiben von Produkten mit gemeinsamen Merkmalen können in BMEcat über Klassifikationssysteme gespeichert und auf Produkt-Ebene zugewiesen werden. Auf diese Weise können Attribute zentral verwaltet werden. Für den Bereich eCommerce bietet das Format diverse Möglichkeiten bis hin zu konfigurierbaren Produkten und die Definition von Logistikdaten.
Die Vorteile im Überblick:
* Vorarbeiten der Felddefinition sind schon erledigt. Felddefinitionen mit Datentypen liegen vor.
* Großes Portfolio möglicher Datenfelder im Standard.
* MUSS und KANN-Felder sind definiert.
* Hierarchien und Attribute sind berücksichtigt.
* Erweiterbarkeit per UDX = Anpassung des Stammdatenspeichers möglich.
* Schnittstellen diverser Plattformen unterstützen BMEcat.
* BMEcat passt zum allgemein anerkannten "Item <-> Attribute" Datenmodell.
* BMEcat kann Item (Artikel) <-> Supplier (Lieferant).
* BMEcat kann Item <-> Buyer (Kunde).
* BMEcat kann Item <-> Location (Zielmarkt).
* BMEcat kann Mehrsprachigkeit: In einem Stammdatensatz können die Felder Kurz- und Langbeschreibung, Schlagworte, Merkmalsbezeichnungen und Werte mehrsprachig gespeichert werden.
* BMEcat kann Klassikationen beinhalten (auch mehrere)
* BMEcat kann Attribute zuweisen (auch Sets)
* BMEcat beinhaltet Item <-> Item Relationen (z.B. ähnliche Produkte)
* Updates anderer Syteme: Dazu kommt, dass sandardisierte Transaktions- und Update-Mechanismen abgebildet werden. Transaktionen definieren, welche Teile eines Stammdatensatzes übertragen werden und wie diese Daten im Zielsystem zu verarbeiten sind. Durch Transaktionen wird die Datenmenge der übertragenen Daten bei Updates erheblich reduziert.
* BMEcat kann leicht transformiert werden: erforderliche Zielformate für interne wie externe Systeme sind einfach umsetzbar.
Umsetzung einer an BMEcat angelehnten Datensatzdefinition
Hier ein Beispiel für die Umsetzung eines Produkts, das vollständig nach BMEcat definiert wurde.

Dieser Artikel setzt sich wie folgt zusammen:
* Statische Attribute (Artikelnummer)
* Klassifikation: Dynamische Attribute (Höhe, Breite, Tiefe, Farbe)
* Klassifikation: Hierarchie
* mehrere Sprachen
* mehrere angehängte Dateien
* ähnliche Produkte
* Staffelpreise
* Preisgültigkeit
* Mehrere Zielmärkte
Fazit
BMEcat erscheint geeignet für den strategischen Einsatz mit Tiefenwirkung bei der Anpassung vorhandener Strukturen und hat auch Vorbildcharakter für die Konzeption zukünftiger Systemlandschaften. Hervorragend ist die Kompatibilität mit Systemen, die Daten nach dem "Item2Attribute-Modell" in Kombination mit Klassifikationssystemen vorhalten. Projektkosten können durch die in weiten Teilen aus dem Standard zu übernehmenden Definitionen erheblich reduziert werden.
Contact
Sepia GmbH & Co. KG
Ernst-Gnoss-Strasse 22
D-40219 Düsseldorf - Germany
Phone: +49 211 51 419 75
Phone alternative: +49 211 74 958 712 0
E-Mail: info@sepia.de
Looking for consultation or a web demo?
Get it here.